Evaluating AI Classification of AI-Generated Cat Images
Introduction
Written and researched by Lucas Lin.
This assignment explores how well AI can recognize and classify different qualities in cat images generated by other AIs on CIVITAI. By analyzing how well AI models can identify predefined attributes such as Realistic, Artistic, Surreal, Humorous, and Abstract, I aim to assess the accuracy and reliability of these models in interpreting visual data. This not only evaluates the technical performance of AI but also explores the broader implications of AI-driven image classification in the context of digital content creation.
1. Building the Corpus
1.1 Corpus Desciption
- Source: Generated AI Images from CIVITAI, a site where people share and download AI models.
- Number of Images: 99
- Number of Images with Prompt: 67
- Attributes: Realistic, Artistic, Surreal, Humorous, Abstract (only tagged on images with prompts)
- Organizaiton: Everything’s sorted into folders named after those five categories.
1.2 Data Gathering
I used the IMAGE DOWNLOADER extension to pull 99 of the latest AI-generated cat images from CIVITAI (from May 1, 2025). The default weekly filter gave me a good slice of what’s trending right now. After that, I went back manually and checked each one for its prompt, writing them down if they existed—super important for what comes next.
1.3 Organizing Corpus
To give the analysis some structure, I sorted the images into five main styles: Realistic, Artistic, Surreal, Humorous, and Abstract. I didn’t pick these out of nowhere. I asked KIMI to read all the prompts and suggest category sets a few times, then chose the one that made the most sense. I let KIMI guide the classification because I wanted to lean into the logic of the machine—categorizing more from the prompt’s perspective than my personal interpretation of the images. I created a duplicate folder with the chose subfolders of the images in categoriazation in it. Here’s the gist of each category:
-
Realistic and Photorealistic → Focused on cats that look super lifelike—clear textures, natural lighting, that sort of thing.
-
Artistic and Illustrative → More expressive images—painterly, stylized, or visually interpretive with less emphasis on realism.
-
Surreal and Fantasy → Weird, dreamy, exaggerated—images that feel like they come from an alternate universe.
-
Humorous and Meme-like → Light-hearted and playful, sometimes outright absurd. These are designed to entertain.
-
Abstract and Minimalist → Simpler, more symbolic compositions. Think shapes, colors, forms—less about representing reality.
Because I wanted to evaluate how AI understands and responds to prompts, organizing images by prompt made more sense than sorting purely by visual traits.
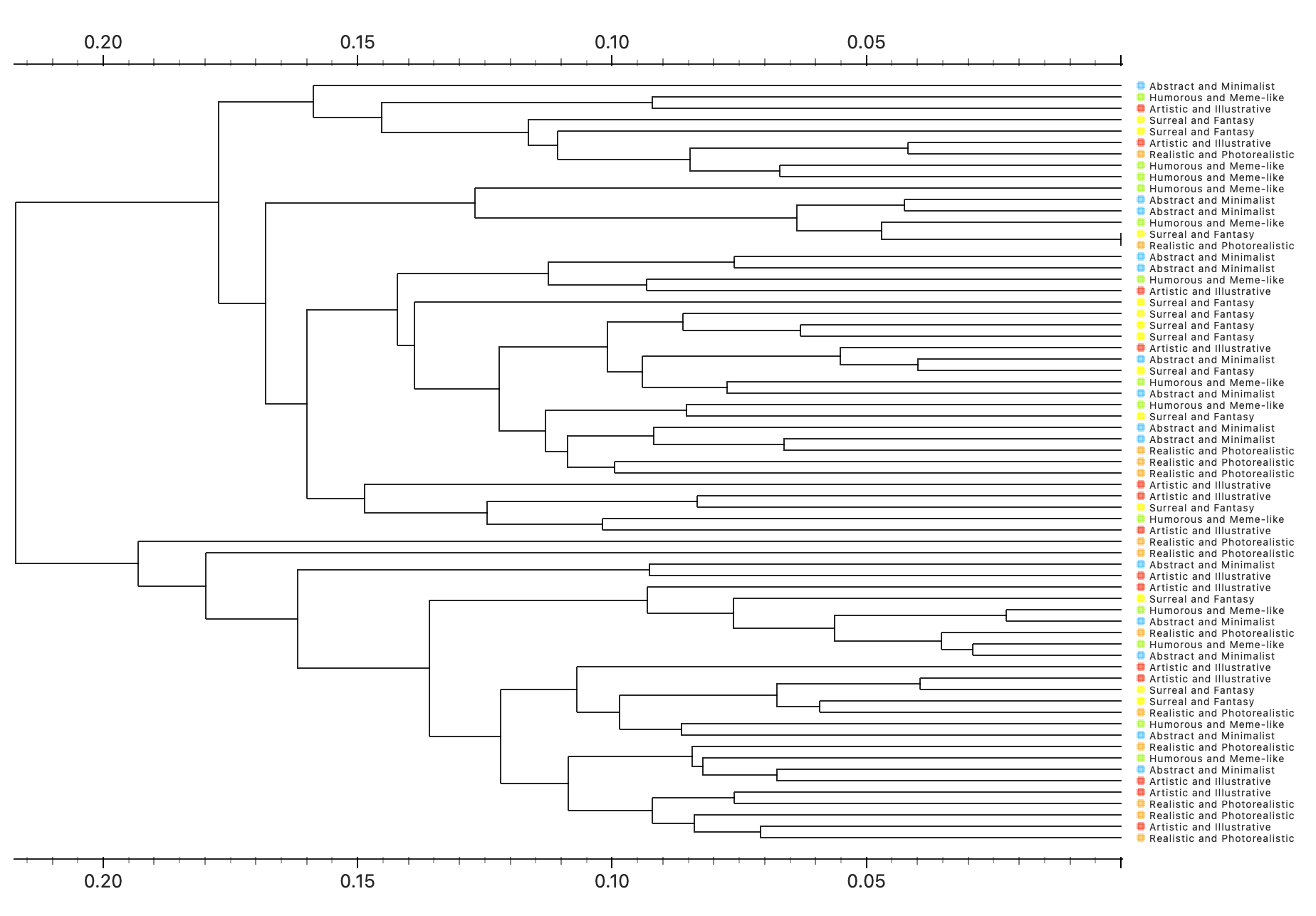
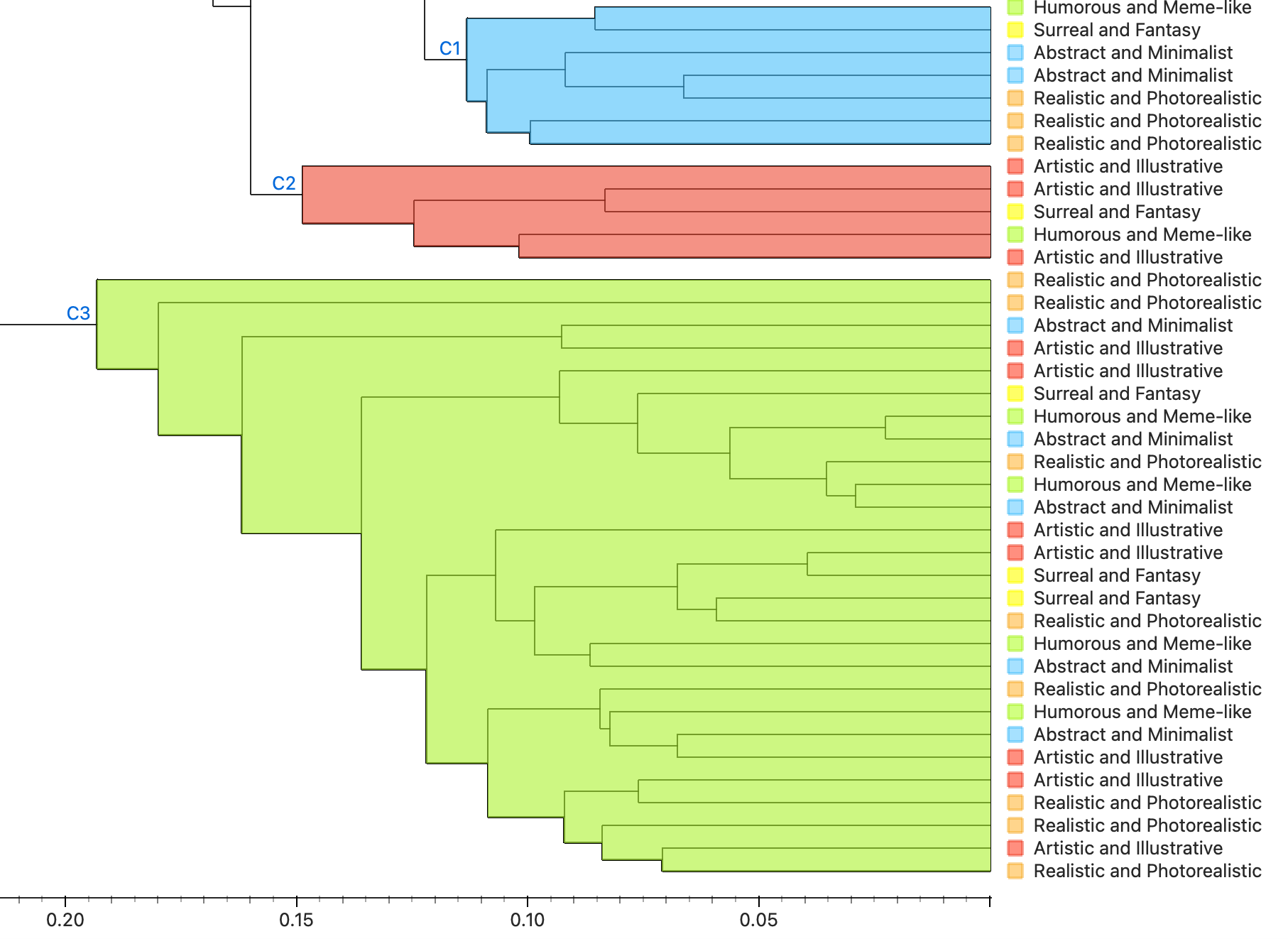
2 Clustering Exercise (Organe Data Mining)
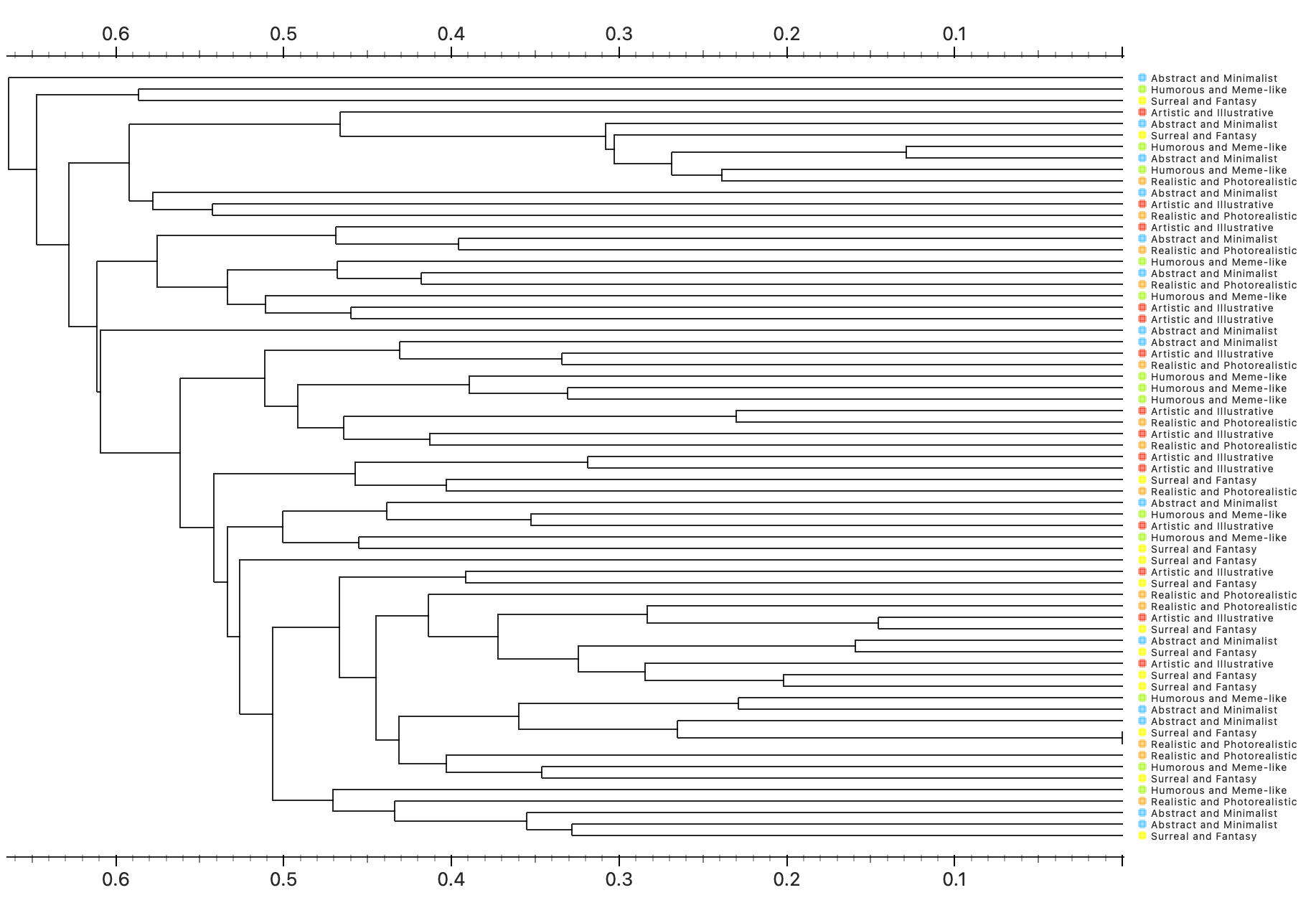
2.1 Different Algorithms Clustering
To begin, I clustered the images without their labels—just to see how the algorithm would naturally group them. This follows what Impett and Offert (2024) talked about: when you’re reading a corpus through a neural net, you’re also kind of letting the machine read it back to you.
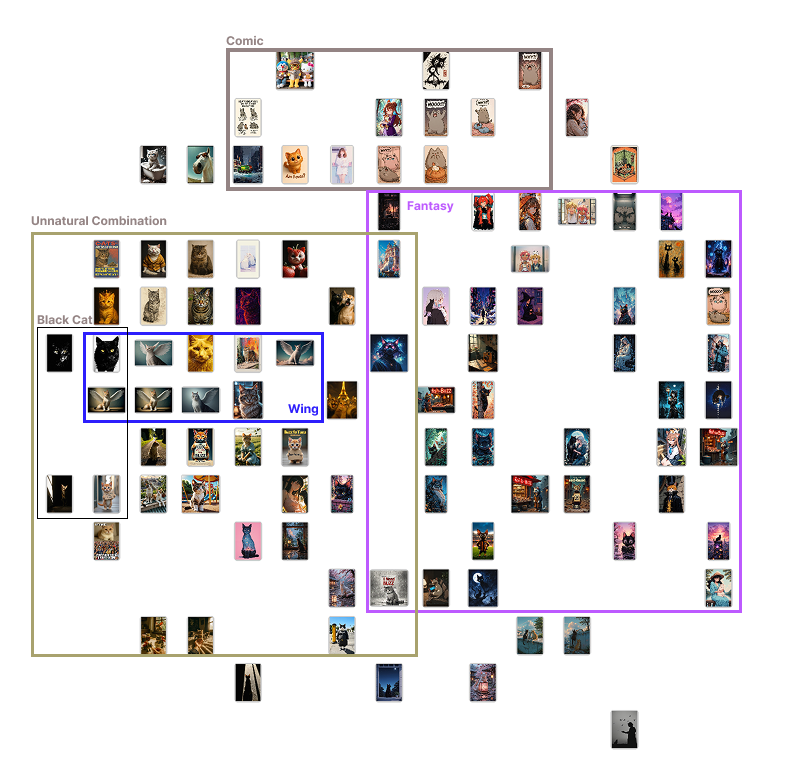
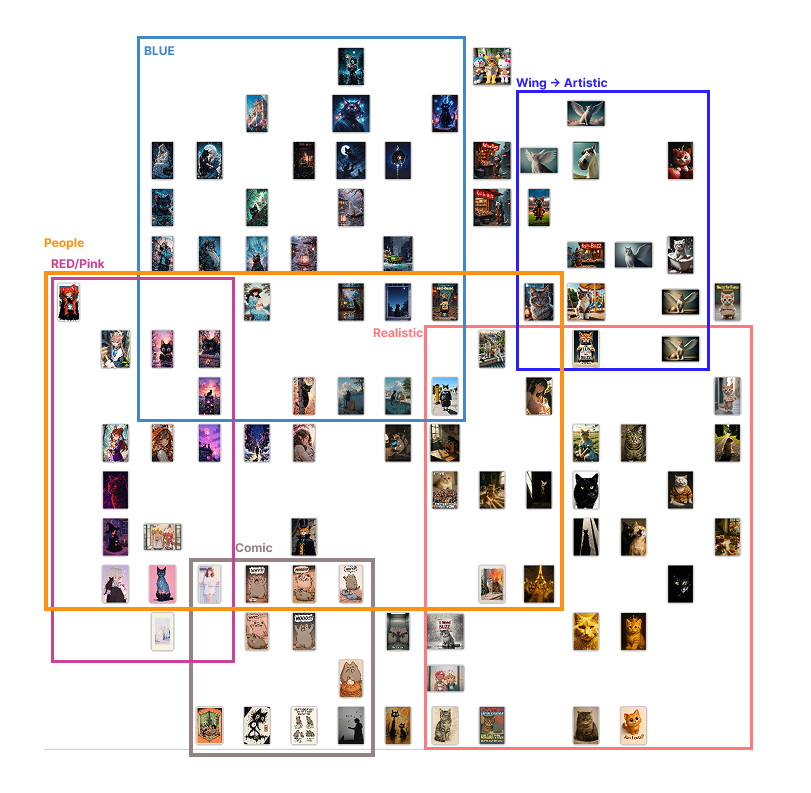
Here are some snapshots of what came out of that:
| Cluster Screenshot | Algorithm |
|---|---|
 |
Inception V3 |
 |
SqueezeNet |
 |
Painters |
 |
DeepLoc |
What I noticed:
Inception V3Seemed to pick up on object likeness—e.g., black cats were often grouped together.SqueezeNetOrganized more by thematic cues—narrative elements, context, or tone.themes.DeepLocPrioritized light and color distribution. Darker images were clustered toward the top left, lighter ones toward the bottom right.PaintersFocused on type and color palette—essentially a visual art-style clustering.
Each clustering algorithm “read” the images differently. These patterns echoed Impett and Offert’s point: different models carry different cultural biases and logics. It’s not about right or wrong—it’s about recognizing that what a model notices says something about its architecture and training history.
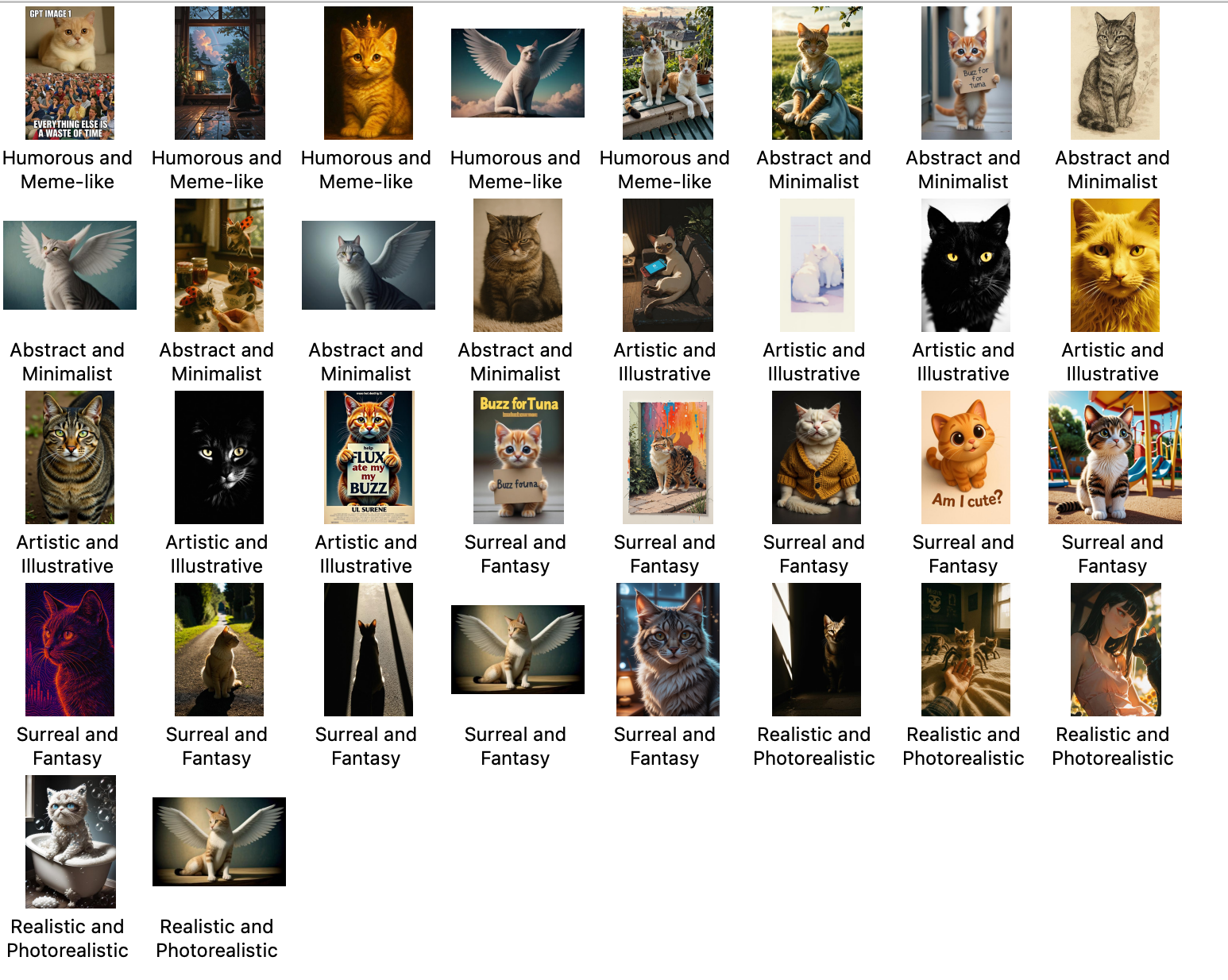
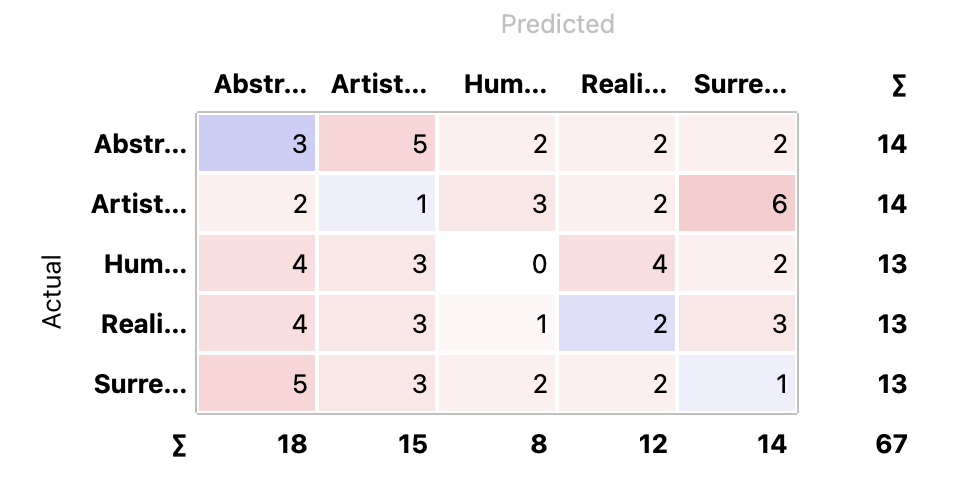
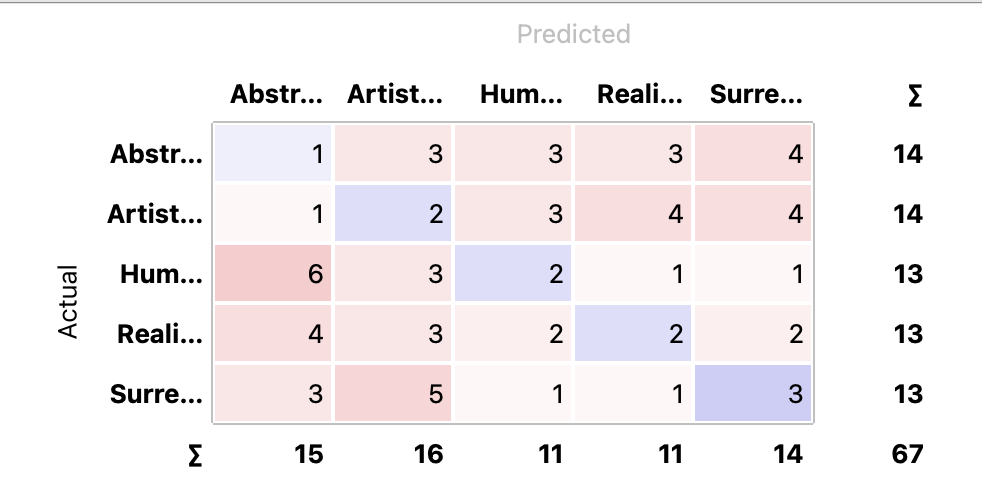
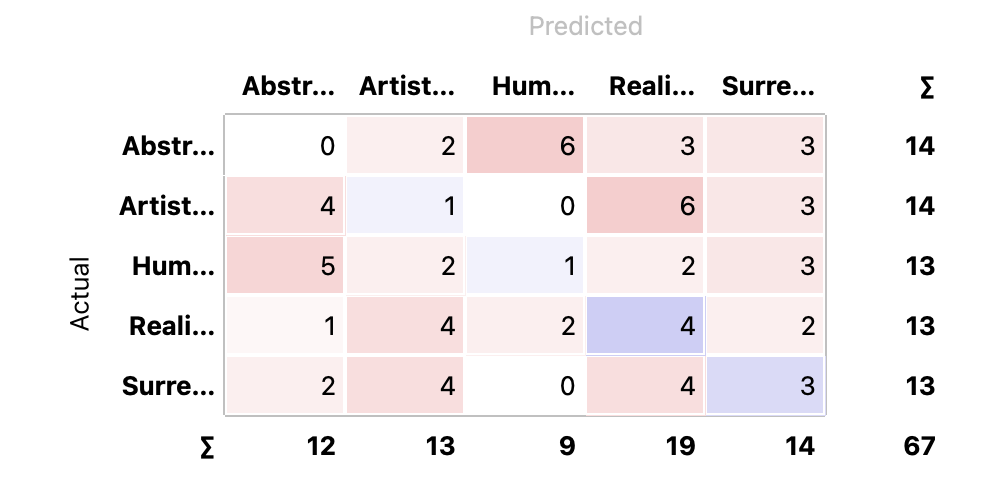
3 Classification & Consfusion Matrix
3.1 Categorizing Images
As previously mentioned, I developed a classification system based on the attributes: Realistic, Artistic, Surreal, Humorous, and Abstract. These categories were determined by analyzing the prompts of the images with the assistance of KIMI.
3.2 Prediction
I anticipated that the AI would accurately identify some classifications, given that the images were generated based on specific descriptive wording. However, the results did not fully meet my expectations, as the AI’s classifications were inconsistent and did not clearly identify some categories.
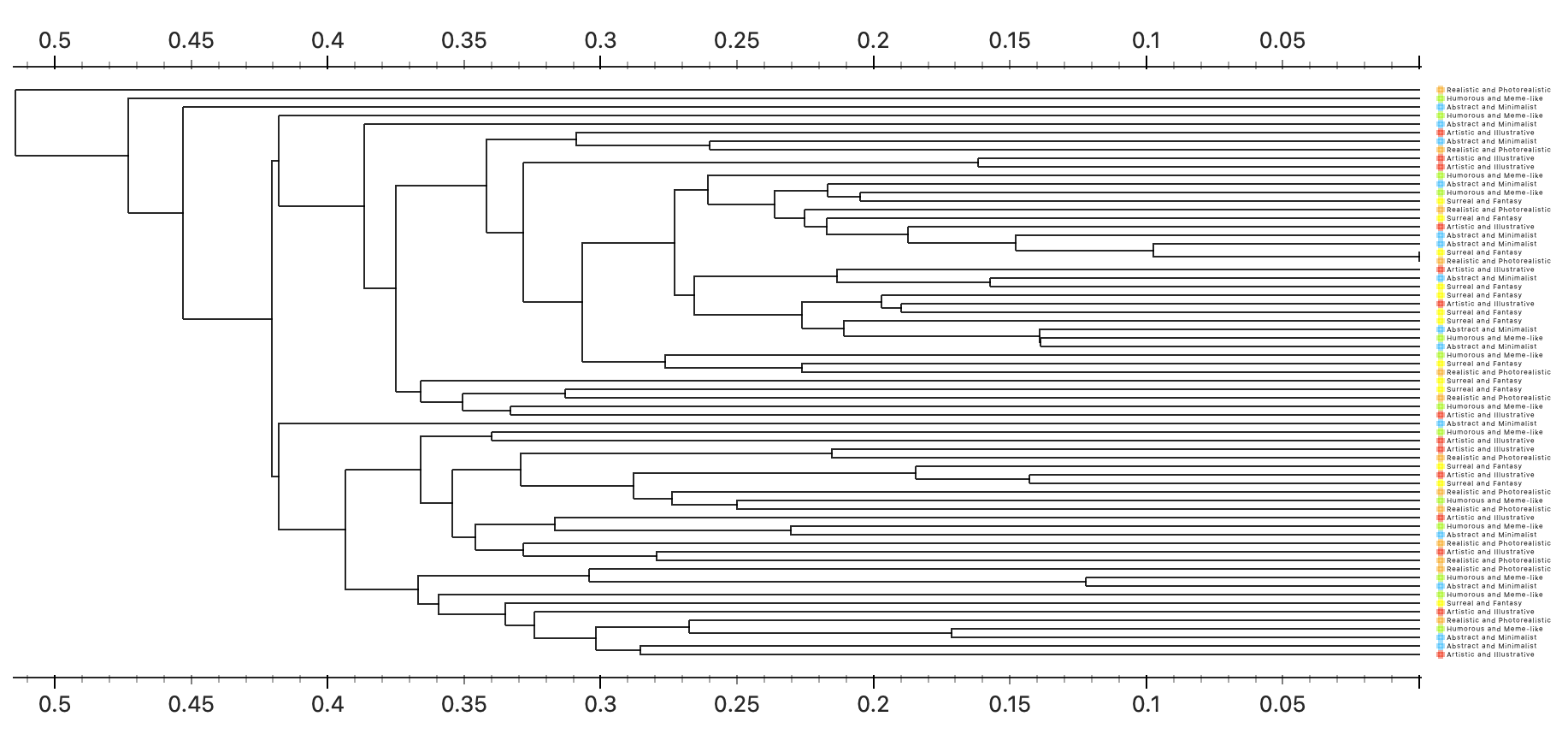
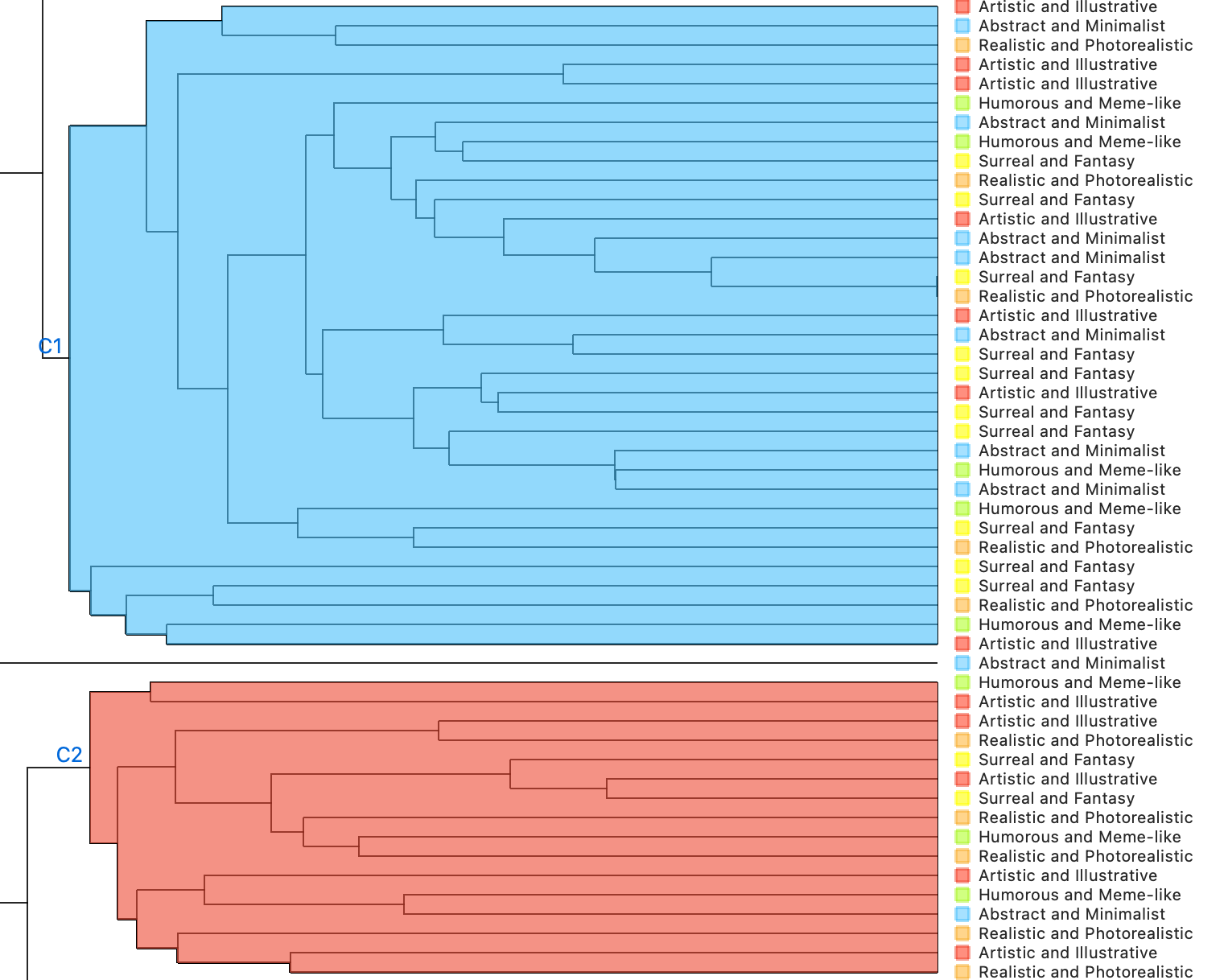
3.4 Result
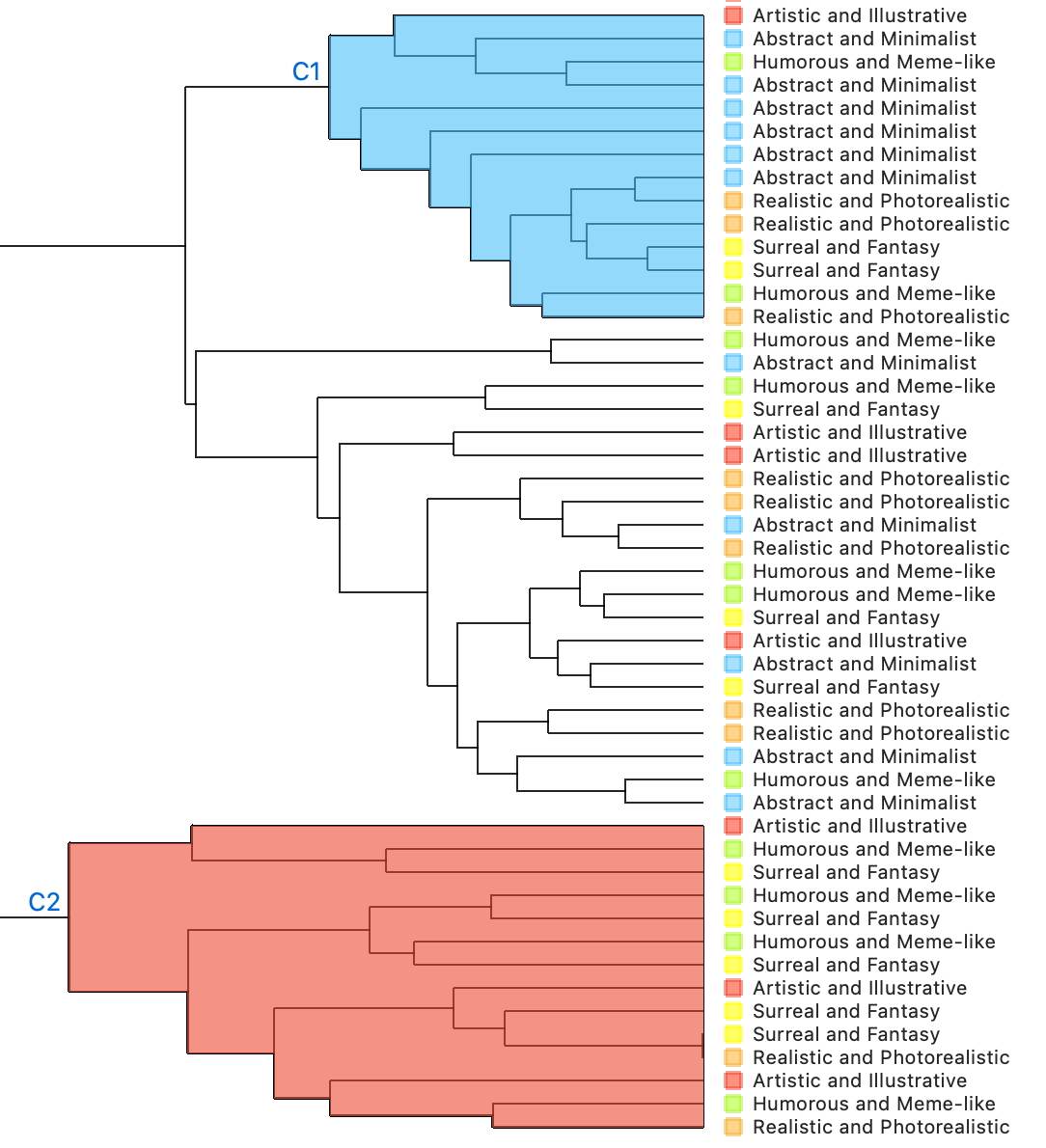
A. Inception V3 |
|
|---|---|
 |
 |
 |
C1. Most Surreal Fantasy but it seems that it attempted to categorize by how solid the color or texture is in this cluster |
 |
C2. Artistic illustrative is the most in this cluster but what the algorithm did was cluster the more animalistic playful images in this cluster |
 |
Inception V3 did a better job recognizing abstract stuff, but really struggled with identifying humor, surreal elements, and artistic styles. |
Inceptionv3was able to tell playful and serious apart, but struggled to match my defined categories.
B. SqueezeNet |
|
|---|---|
 |
 |
 |
C1: Captured dramatic lighting well, but didn’t recognize the artificial or staged quality. |
 |
C2: Did well with Artistic—most grouped images had detailed eyes/hair and self-portrait energy. |
 |
C3: Grouped anime/manga styles together—though these were actually intended to be Realistic based on prompt. Suggests a different idea of “realism.” |
 |
SqueezeNet performed better than Inception V3, especially in identifying thematic and visual traits across most categories. Still had issues with nuance in artistic categories. |
This model clustered by shared traits and atmosphere. Not perfect, but closer to my expectations.
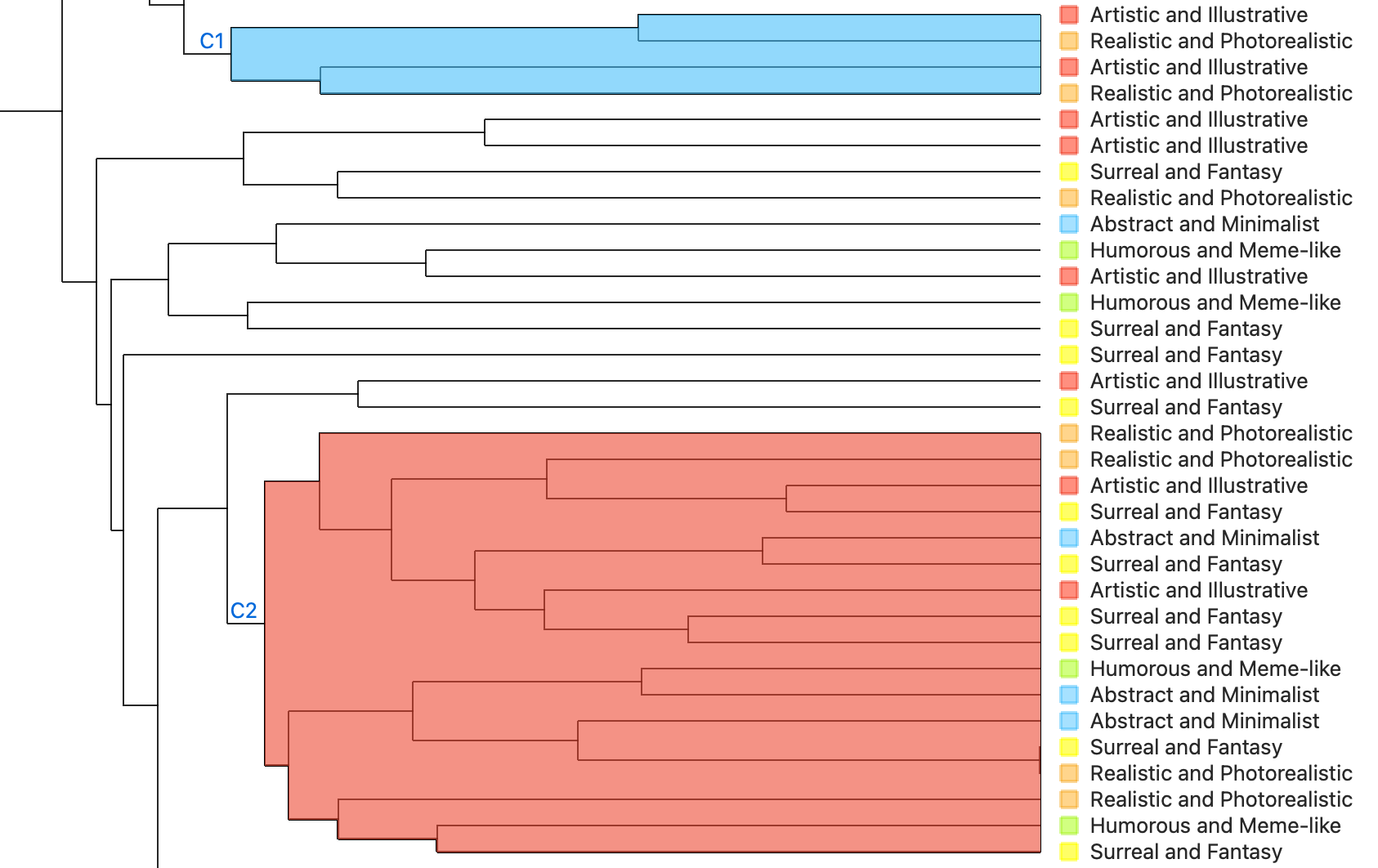
C. Painters |
|
|---|---|
 |
 |
 |
C1: Capture a Anime-style digital art with realistic details |
 |
C2: Features creative cat like images that are not common sense, plaing around with merging cat with another feature. |
 |
Painters does a better job in distinguishing between realistic Photorealistic and surreal fantasy. While the other types it does not do a great job. |
Paintersmodel performs well in identifying anime-style digital art with realistic elements, as well as imaginative, non-literal cat depictions—such as cats creatively merged with other features or environments. This strength is particularly evident in the Surreal and Fantasy category, where Painters excels at capturing the visual essence and conceptual playfulness of the style. However, the model struggles to clearly distinguish between other styles, such as Realistic/Photorealistic and Abstract/Minimalist. This indicates that while Painters is effective at recognizing stylized or fantastical imagery, it needs improvement in parsing the more nuanced or overlapping characteristics of other artistic categories.
D. DeepLoc |
|
|---|---|
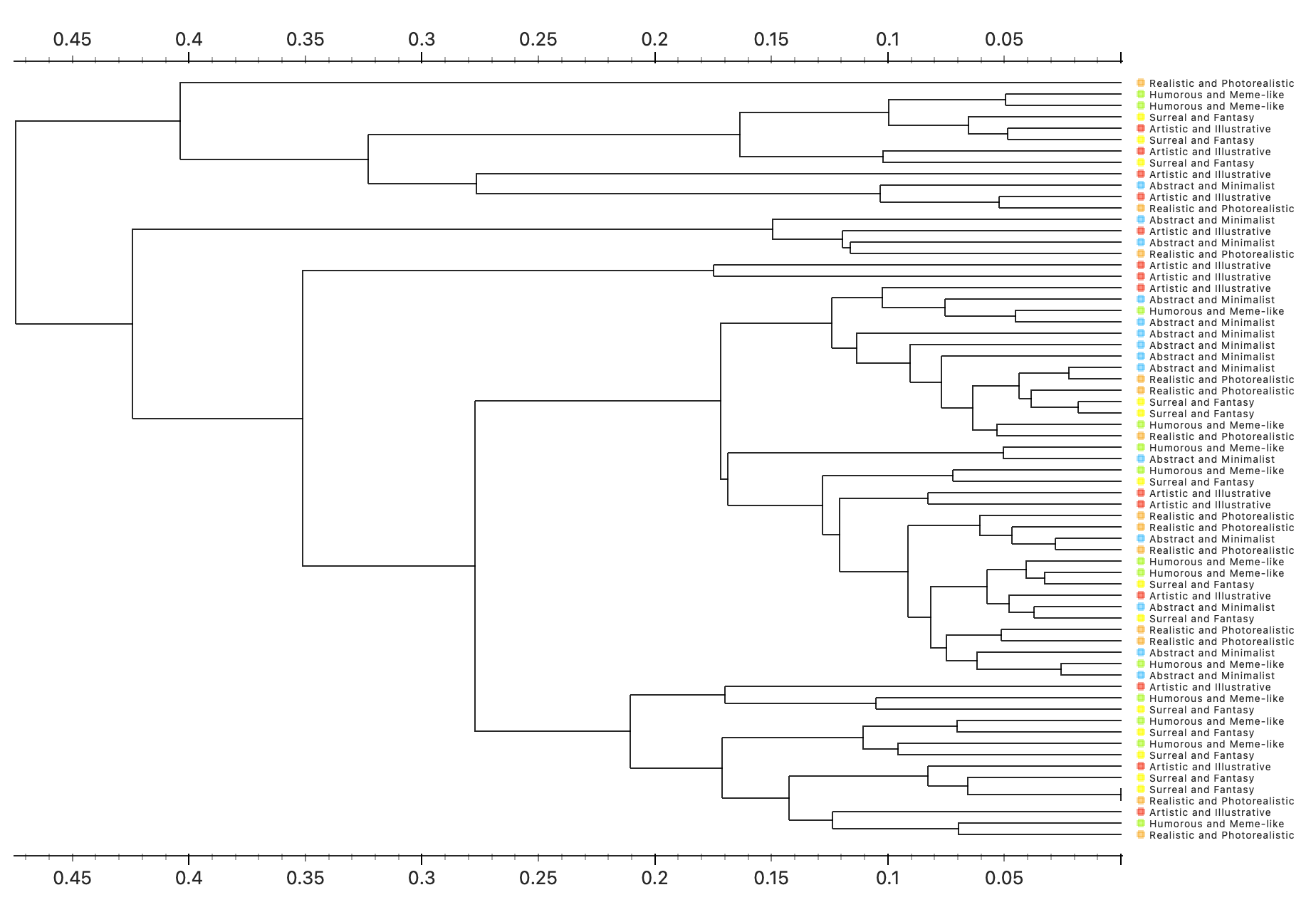 |
 |
 |
C1: Cute bright colored cat images with a deep story vibe to them |
 |
C2: Playful variations of the cat. Dark color like a poster for display. |
|
In terms of average it does a much better job than the other algorithms. It has more balanced results with no weakness. |
DeepLocdoes not exhibit any major weaknesses, suggesting a robust and consistent algorithmic approach to recognizing diverse visual styles. Its performance stands out for being steady and well-rounded rather than excelling only in specific areas.
Upon reviewing the classification results, several insights emerged:
- Algorithm Performance: The performance of the algorithms varied significantly. While SqueezeNet showed a strong ability to identify thematic elements and common traits, Inceptionv3 struggled with accurate categorization based on the predefined attributes.
- Misclassification Accuracy: The AI’s ability to accurately classify images into the established categories was inconsistent. Some images could be considered for multiple categories but were placed in one due to the AI’s interpretation.
3.4 Reflection
Upon reviewing the classification results, several insights emerged:
- Performance Varies: SqueezeNet was more aligned with the prompt-based categories. Inceptionv3 didn’t pick up on thematic or narrative elements as well.
- Category Boundaries Are Fuzzy: The prompts themselves sometimes contained hybrid or complex descriptions. AI struggled most when an image embodied more than one attribute. The categories I used weren’t always easy to separate cleanly—many images could reasonably fit into more than one. This overlap may have confused the models, but that wasn’t necessarily a flaw in their design. My main goal wasn’t perfect classification—it was to explore how different AI systems perceive, interpret, and organize creative outputs, even when the boundaries are fuzzy.
- AI Sees Differently: Some classifications were “wrong” by prompt label but “logical” when considering visual similarity. That’s telling.
Example:
| Image | Prompt |
|---|---|
 Category: Realistic and Photorealistic Category: Realistic and Photorealistic |
raw analog candid grainy photo 3 cute fluffy kitten/spider hybrids with fluffy spider legs (no paws), ultra high definition, on a cosy room bed, sunny morning light, we can see a human hand like a pov from the bed, one of the hybrids is climbing on the hand while other climb the bed, its a pov from me waking up so we can see the raw form of the body under the blanket, the room seems to be of a goth teem from the 90’s |
The image and prompt often feel like two entirely separate entities. One opens a world of interpretation and imagination, while the other imposes a frame or limit. A single description can lead to many different visual outcomes, just as a single image can inspire countless interpretations. Ideally, you’d expect a basic alignment between what a prompt describes and what the image delivers—but that’s not always the case.
For instance, the AI might classify an image with a clearly fantastical prompt as “realistic” because it’s reading the visual style rather than the concept. It focuses on lighting, texture, resolution—things that signal photographic realism—even if the content itself (like a cat with dragon wings) is entirely fictional. The AI reads “realness” as a surface quality, not a thematic one.
This shows a fundamental split in how the AI processes data: when categorizing, the model leans on textual information, using keywords to identify the intended style. But when clustering, the model works visually, grouping based on form, color, and visual similarity—not on what the image is “about.”
This difference reveals a core challenge in machine vision: the gap between semantics (meaning) and aesthetics (appearance). As Arnold and Tilton argue in Distant Viewing, computational methods can analyze large image corpora efficiently, but interpretation still depends heavily on context. Our results echo that—AI can sort images by how they look, but it struggles with how they mean.
Ultimately, while AI models have become skilled at recognizing visual features, they’re still developing an understanding of how visual content and textual intent relate. There’s a gap between prompt and picture, between description and depiction. Until models can bridge that gap—understanding both what is seen and what is meant—their classifications will remain just approximations of human interpretation.
4 Multimodal Analysis (CLIP/DV Explorer)
4.1 Generate Captions
Using distant viewing tools, I analyzed a series of AI-generated images by inputting prompts into image generation models, then comparing the DV Explorer Image Captioning to the original prompts. Additionally, I applied Image Classification to compare the predicted categories to the intended content and visual themes of the images.
Failed Results and Mismatches:
| Image | Prompt | Category Predicted |
|---|---|---|
 Predicted Caption:a cat and a dog are in the snow. Predicted Caption:a cat and a dog are in the snow. |
IMAGE 1: masterpiece, best quality, absurdres, volumetric lighting, dynamic lighting, cinematic lighting, [[dynamic pose]], upper body shot, 1girl, solo, from behind, ((from above)), looking side, inner hair color, grey hair, gradient hair, long hair, messed hair, brown eyes, , ultra detailed eyes, small breasts, [[[abs]]], (office outfit), medium skirt, thick black pantyhose, pumps, rimless round glasses, earrings, ear pierces, BREAK [[skindentation]:0.5], chubby, ((chubby thick legs), thick legs, chubby legs), thick calf, [[muscular legs]:0.95], petting calico cat, black cat, white cat, tuxedo cat, (simple background, simple gradient pastel turquoise background), detailed eyes, fl4t, MF9f, perfect hands, Bright_illu, sparkle, too many light particles, <lora:sdxl_turbo_weghts_beta_v0_1_0:0.95> <lora:Namori_Illustrious:0.8> <lora:Bright_style:0.75> <lora:fl4t:1.2> <lora:MF9fMTFYeA==-noobaiXLNAIXL_epsilonPred_V110_V1-CAME:0.9>, 「Negative prompt: nsfw, bad quality, worst quality, worst detail, censor, missing fingers, extra fingers, blurry eyes, poorly drawn eyes, skewed eyes, bad anatomy, furry, chubby stomach, pot belly, chibi, child, sketch, signature, text, glossy tights」 | Siamese cat, Siamese (98.80%); Egyptian cat (0.17%); basenji (0.15%); toilet tissue, toilet paper, bathroom tissue (0.13%); paper towel (0.10%) |
 Predicted Caption:a woman with a cat on her head Predicted Caption:a woman with a cat on her head |
IMAGE 2: Masterpiece, ultra-HD, cinematic lighting, photorealistic, impressionism (1.5), high detail, depth of field, (blurred background), (dramatic lighting),masterpiece, best quality, very aesthetic,8k,masterpiece, best quality,realistic, masterpiece, best quality, 8k, simple_background, half close-up, sexy pose, long black hair, straight hair,blunt bangs, red eye makeup, blushing, asian girl, small head, pretty girl, korean girl, extacy on face, ((slim body)), (small breasts), Dynamic angle, Dynamic pose, sfw, portrait, girl, pastel pink sundress, in a field of sunflowers. holding black cat. smiling. happy. sunset 「Negative prompt: Female tongue, female tongue out, Neck grab, worst quality, low quality, displeasing, text, , watermark, bad anatomy, text, artist name, signature, hearts, deformed hands, missing finger, shiny skin,child,children」 | spider web, spider’s web (74.97%); electric fan, blower (12.09%); comic book (1.51%); parachute, chute (1.22%); fountain (0.59%) |
 Predicted Caption: a woman dressed in a costume with a red hat. Predicted Caption: a woman dressed in a costume with a red hat. |
IMAGE 3: Masterpiece, newest,absurdres,incredibly absurdres, best quality, amazing quality, very aesthetic, painterly, surreal, 1girl, troll face, tress ribbon, fringe trim, twintails day, tassel earrings, photo inset, cat print, hair tubes, (big hair:1.3) <lora:ka_marukogedago:1> k4_illu, abstract, traditional media, scan, blending, painting (medium), oil painting (medium) <lora:KonYa666:1> kony4666 <lora:Lifeline_Illu_Edition:1> LL-Illu 「Negative prompt: worst quality, bad quality, low quality, anatomical nonsense, bad anatomy,interlocked fingers, extra fingers,watermark, jacket」 | kimono (49.81%); comic book (5.41%); pinwheel (4.05%); pillow (3.69%); parachute, chute (3.51%) |
 Predicted Caption: a white teddy bear sitting on top of a white building Predicted Caption: a white teddy bear sitting on top of a white building |
IMAGE 5: Ethereal fantasy concept art of anime artwork Baroque, “A realistic painting of The Cat and its Rococo Palace in the sky with blue flowers and clouds, in the style of Krenz Cushart, Moebius, and Muchain, Prismatic, Rococo, Pearlescent, reflective, shimmering, highly detailed, masterpiece, dreamy, concept art, Cinema lighting, 8k, trending on artstation”, masterpiece, best quality, very very very very aesthetic,absurdres, <lora:Wild_Anime_2025:0.7>, <lora:Poster_XL:0.15> <lora:extremely_detailed:0.7> extremely detailed , <lora:aidmaImageUpgraderSDXL-v0.3:0.5> aidmaImageUpgrader, <lora:add-detail-xl:0.7>, <lora:HyperdetailedColoredPencilIl:0.15> ArsMJStyle, Colored pencil hyperdetailed realism, <lora:ppw_v7_animv4_1_r2:0.3>,, dramatic, exuberant, grandeur, baroque art, anime art style, anime digital art, expressive anime art, dynamic composition, anime style, vibrant, studio anime, highly detailed, anime style, key visual, vibrant, studio anime, highly detailed, magnificent, celestial, ethereal, painterly, epic, majestic, magical, fantasy art, cover art, dreamy.「Negative prompt:(hand:1.5), <lora:badanatomy_AutismMix_negative_LORA:1> bad anatomy, bad hands, bad feet, CyberRealistic_Negative-neg, NEGATIVE_HANDS, EasyNegativeV2blurry,, ugly, deformed, noisy, blurry, low contrast, signature, watermark, photo, photorealistic, realism, ugly, off-center, deformed, 35mm film, dslr, cropped, frame, worst quality, low quality, lowres, JPEG artifacts, photo, deformed, black and white, realism, disfigured, low contrast, photographic, realistic, realism, 35mm film, dslr, cropped, frame, text, deformed, glitch, noise, noisy, off-center, deformed, cross-eyed, closed eyes, bad anatomy, ugly, disfigured, sloppy, duplicate, mutated, black and white.」 | Church, church building (40.15%); umbrella (15.50%); fountain (14.48%); palace (2.40%); chainlink fence (2.37%) |
 Predicted Caption: a dog sitting on a sidewalk next to a man Predicted Caption: a dog sitting on a sidewalk next to a man |
IMAGE 11: A realistic picture, cute muscular orange cat wearing hoodie with apron standing in front of his fish stall in fish market, on top of his street stall ,The neon signs glow warmly reads “fish for Buzz “, creating a nostalgic atmosphere (dynamic lighting:1,0), background, ruined market after war, in midle eastern country ,(intricate details,naturalism,hyperdetailed,hyperrealistic:1.55) mvpstrCE style ((((Display the text help me with buzz!” on a movie poster)))). no human. | Egyptian cat (71.53%); tabby, tabby cat (7.01%); tiger cat (5.90%); lynx, catamount (3.04%); butcher shop, meat market (2.11%) |
 Predicted Caption: a cat sitting in a candle lit Christmas tree. Predicted Caption: a cat sitting in a candle lit Christmas tree. |
IMAGE 20: Neon, smooth edges, Ultra-detailed, photorealistic scene of a tranquil Japanese cherry blossom garden at dusk under heavy rain. A sleek white cat with smooth fur and graceful posture perches on the edge of a small. | Egyptian cat (44.34%); Siamese cat, Siamese (10.58%); lynx, catamount (5.34%); birdhouse (4.83%); lampshade, lamp shade (3.15%) |
 Predicted Caption: two stuffed animals are sitting on a wall. Predicted Caption: two stuffed animals are sitting on a wall. |
IMAGE 22: Embedding:IllusP0s, no russian, elevator, holding weapon, assault rifle, no humans, pusheen<lora:no russian_illustrious.safetensors:1.0:1.0> <lora:PusheenIXL.safetensors:0.7:0.7> 「Negative prompt embedding:IllusN3g, twins, clones.」 | sandal (47.68%); handkerchief, hankie, hanky, hankey (16.31%); iron, smoothing iron (4.79%); rifle (1.05%); shoe shop, shoe-shop, shoe store (0.86%) |
 Predicted Caption: a white cat with a bird on it. Predicted Caption: a white cat with a bird on it. |
IMAGE 24: (Masterpiece:1.2, high quality), cat, :3, <lora:cat_20230627113759:0.8> angel wings「Negative prompt: EasyNegative , badhandsv5-neg.」 | Egyptian cat (86.46%); window screen (3.60%); tabby, tabby cat (2.72%); tiger cat (2.12%); lynx, catamount (0.75%) |
 Predicted Caption: a stuffed bear with a red flower in its mouth. Predicted Caption: a stuffed bear with a red flower in its mouth. |
IMAGE 33: Cinematic still detailed realistic close up of a strawberry shaped like a kitten, sitting, natural light . emotional, harmonious, vignette, 4k epic detailed, shot on kodak, 35mm photo, sharp focus, high budget, cinemascope, moody, epic, gorgeous, film grain, grainy, (masterpiece), (best quality), (ultra-detailed), detailed realistic close up of a strawberry shaped like a kitten, sitting, natural light, illustration, disheveled hair, detailed eyes, perfect composition, moist skin, intricate details, earrings, detailed realistic close up of a strawberry shaped like a kitten, sitting, natural light, deep focus, intricate, elegant, highly detailed, very beautiful, symmetry, great composition, sharp, fine detail, cinematic, unique, rich dynamic, lovely colors, cute, artistic, epic, brilliant, complex, cool, ambient, background, full color, professional, extremely inspirational.「Negative prompt: text, motion lines, effects, border, frame. (worst quality, low quality, normal quality, lowres, low details, oversaturated, undersaturated, overexposed, underexposed, grayscale, bad photo, bad photography, bad art:1.4)」 | hamster (36.50%); goldfish, Carassius auratus (6.17%); plastic bag (5.86%); Persian cat (5.28%); agaric (3.69%) |
 Predicted Caption: a cat sitting on top of a crowd of people. Predicted Caption: a cat sitting on top of a crowd of people. |
IMAGE 36: Generate a super viral and funny meme with the text: “GPT Image 1 - everything else is a waste of time.” | window screen (28.97%); bathing cap, swimming cap (11.27%); Persian cat (8.44%); paddle, boat paddle (6.71%); Egyptian cat (2.93%) |
 Predicted Caption: a cat with a blue tag on it. Predicted Caption: a cat with a blue tag on it. |
IMAGE 40: Masterpiece, best quality, ultra high res, beautiful, visually stunning, elegant, incredible details, award-winning painting, contrast, deep shadow, tiger kitten, (bright tan theme), glowing, neon, (fluff:1.2), crown, short hair, white, detailed, realistic, 8k uhd, high quality, sbfte, Midjourney_Whisper, GLSHS | window screen (68.72%); tabby, tabby cat (22.85%); tiger cat (3.02%); Egyptian cat (1.70%); lynx, catamount (0.72%) |
 Predicted Caption: a doll with a stuffed animal on it. Predicted Caption: a doll with a stuffed animal on it. |
IMAGE 43: Girl,original,ahoge,animal,animal ear fluff,animal ears,black bow,black hat,blue neckerchief,blue necktie,blush,bow,brown hair,cat,fang,grate,hair ornament,hairclip,hat,heterochromia,industrial pipe,long hair,looking at viewer,mole,mole under mouth,neckerchief,necktie,open mouth,outdoors,plaid,plaid bow,plant,potted plant,purple eyes,sewer grate,skin fang,smile,solo,tile floor,tiles,window,wooden box,green eyes,shirt,white shirt,beret,animal on head,hair between eyes,sitting,cat ears,on head ,masterpiece,best quality,amazing quality.「Negative prompt: bad quality,worst quality,worst detail,sketch,censor.」 | kimono (14.86%); comic book (11.03%); Windsor tie (4.86%); cowboy hat, ten-gallon hat (4.09%); jersey, T-shirt, tee shirt (3.93%) |
 Predicted Caption: a statue of a man with a clock on his head. Predicted Caption: a statue of a man with a clock on his head. |
IMAGE 50: Score_9, score_8_up, score_7_up, (solo), sfw BREAK 1girl, Ember (ESO), anthro, feline, black and white fur, cat tail, black hair, yellow eyes, slim, breasts, (black armor:1.2), pants, hood, (hugging wizard’s staff:1.2), BREAK shy pose, big eyes, small pupils, ((scared)), looking side, on old cemetery, trees, orb of light floating above her head, horror background, summer, night, darkness, thick mist, beautiful night sky, extremely detailed, cinematic soft lighting, tranquil setting, natural beauty, detailed background, sharp focus, extremely detailed, high detail, dynamic angle, dynamic pose.「Negative prompt: (worst quality, low quality:1.4), (source filmmaker:0.3), duplicate, out of frame, gaping, pubic hair, censored, watermark, text, mutated, aliasing, distorted, ugly, ((extra limbs)), ((poorly drawn eyes)), poorly drawn, low quality, ((out of focus)), ((e621_p_low)), ((signature)), ((watermark)), username.」 | bow tie, bow-tie, bowtie (8.29%); Chihuahua (7.81%); maraca (6.70%); comic book (6.57%); television, television system (5.70%) |
 Predicted Caption:a painting of a penguin on a wall. Predicted Caption:a painting of a penguin on a wall. |
IMAGE 56:((masterpiece, best quality, illustration)), ink art, lo-fi, cute girl voice.「Negative prompt: easynegative, verybadimagenegative_v1.3, By bad artist, negative_hand, 3d, monochrome, bad hands, missing fingers, (low quality, worst quality:1.2)」 | lampshade, lamp shade (70.83%); wall clock (5.92%); magnetic compass (3.43%); dome (1.25%); tray (1.21%) |
 Predicted Caption: a person with a mask on. Predicted Caption: a person with a mask on. |
IMAGE 62: azyup7, source_anime, galaxy cat, night, no humans, glowing eyes. 「Negative prompt: lazydn, 3d.」 | piggy bank, penny bank (14.28%); comic book (10.13%); fountain (7.42%); shower curtain (5.59%); coffee mug (3.72%) |
 Predicted Caption:two cats are playing with a toy bird. Predicted Caption:two cats are playing with a toy bird. |
IMAGE 65: Raw candid grainy photo of whimsical kitten/ladybug hybrids, ultra high definition, scampering across a sun-dappled breakfast table in a cozy kitchen, morning light glinting off jam jars. POV from the table showing a human hand holding a crumb of toast, one tiny cat-bug hybrid with polka-dot wings nibbling the crumb, another climbing a teacup with its fuzzy paws, and a third fluttering near the window, its antennae twitching in the breeze. | cup (22.19%); thimble (8.60%); paper towel (7.79%); goldfish, Carassius auratus (6.77%); saltshaker, salt shaker (6.27%) |
| Predicted Caption: a cat is laying on a bed with a cat. |
IMAGE 66: Raw analog candid grainy photo 3 cute fluffy kitten/spider hybrids with fluffy spider legs (no paws), ultra high definition, on a cosy room bed, sunny morning light, we can see a human hand like a pov from the bed, one of the hybrids is climbing on the hand while other climb the bed, its a pov from me waking up so we can see the raw form of the body under the blanket, the room seems to be of a goth teem from the 90’s. | tarantula (33.97%); quilt, comforter, comfort, puff (33.68%); window screen (4.67%); tabby, tabby cat (3.41%); Egyptian cat (3.03%) |
 Predicted Caption: a cat sitting on top of a book. Predicted Caption: a cat sitting on top of a book. |
IMAGE 67: 90s anti drug PSA, but it’s for catnip. | tabby, tabby cat (86.57%); tiger cat (8.56%); window screen (1.79%); Egyptian cat (0.89%); fire screen, fireguard (0.33%) |
DV Explorer Caption Analysis
The comparison between DV Explorer’s generated captions and original prompts reveals a systematic reduction of complex visual narratives to their most basic elements. For instance, an elaborately prompted “cyberpunk cat bartender mixing neon cocktails” was simplified to “a cat sitting at a table,” while surreal “kitten/spider hybrids in a 90s goth bedroom” became merely “cat on a bed.” This pattern demonstrates the model’s object-centric perception, prioritizing identifiable elements (cats, furniture) over stylistic descriptors, narrative context, or cultural cues. The tool particularly struggled with humor and irony, as seen when it described a meme with explicit “anti-drug PSA for catnip” text as simply “cat on a book.” These limitations align with Arnold & Tilton’s concept of the semantic gap in AI vision systems, where models recognize compositional elements but fail to reconstruct the creative intent or cultural semantics embedded in prompts. The captions’ consistent oversimplification suggests current multimodal systems need enhanced training on stylistic and contextual features to better align with human interpretation of visual culture.
Observations:
-
Caption Mismatch: Most of the AI-generated captions failed to accurately reflect the complex and nuanced content described in the prompts. For example, highly stylized or conceptual images were often reduced to overly simplistic descriptions like “a cat and a dog” or “a woman with a cat on her head.”
-
Category Prediction Inconsistencies: The image classification often focused on superficial elements (e.g., “sandal,” “church,” “electric fan”), ignoring more semantically relevant content. This suggests that models still struggle with context recognition, especially in stylized or surreal images.
-
Semantic Blindness in Stylized Content: The AI’s failure was most evident in anime or fantasy-style images, where specific details—like character design, pose, environment, or emotional tone—were critical to the meaning. Models prioritized generic or misclassified elements, overlooking key narrative signals. Analyze 1–2 examples where AI failed to recognize cultural cues (e.g., a “catgirl” classified generically as “woman”).
-
Surprising Results: Some classifications (e.g., “spider web,” “comic book”) revealed latent pattern biases in the dataset used to train the model, highlighting how irrelevant features can dominate AI perception.
This analysis shows that while multimodal tools like CLIP can offer surface-level understanding of image content, they often lack sensitivity to aesthetic style, narrative intention, and prompt complexity—especially in art or stylized images. This gap reveals current limitations in AI’s ability to semantically align image content with prompt-driven intent, particularly in non-photorealistic domains.
4.2 DV Explorer Zero-Shot Test
To further evaluate multimodal alignment, I tested a subset of images using DV Explorer’s Zero-Shot Classification tool with the same category labels (Realistic, Artistic, Surreal, Humorous, Abstract). The results revealed significant disparities in model performance:
| Results | Comparison |
|---|---|
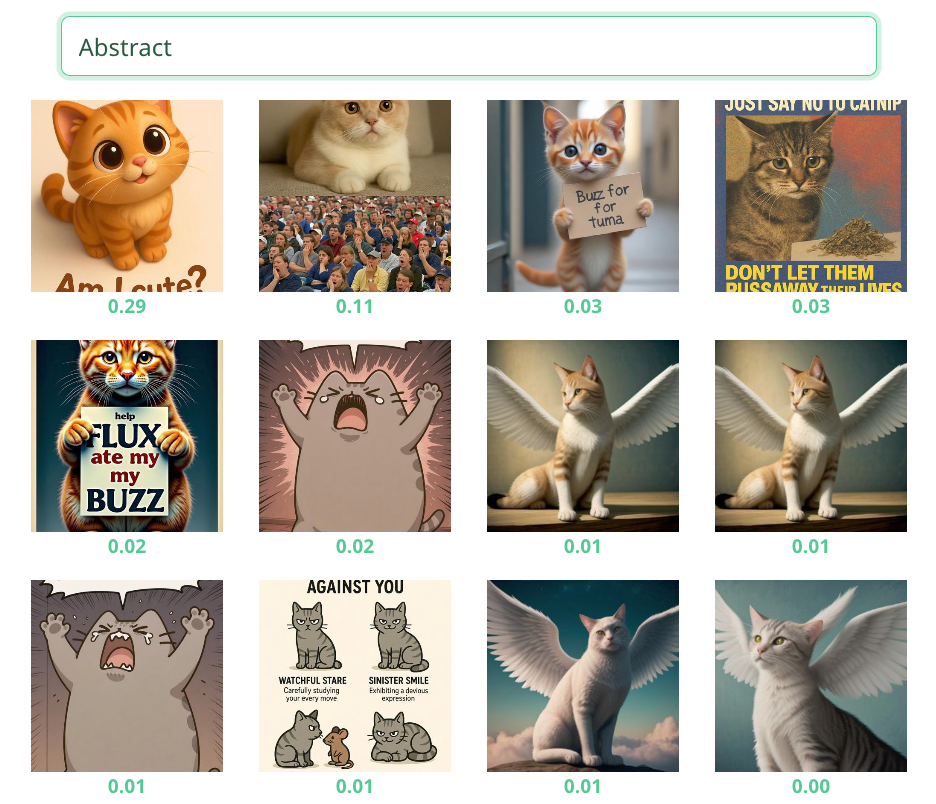 |
Terrible Performance |
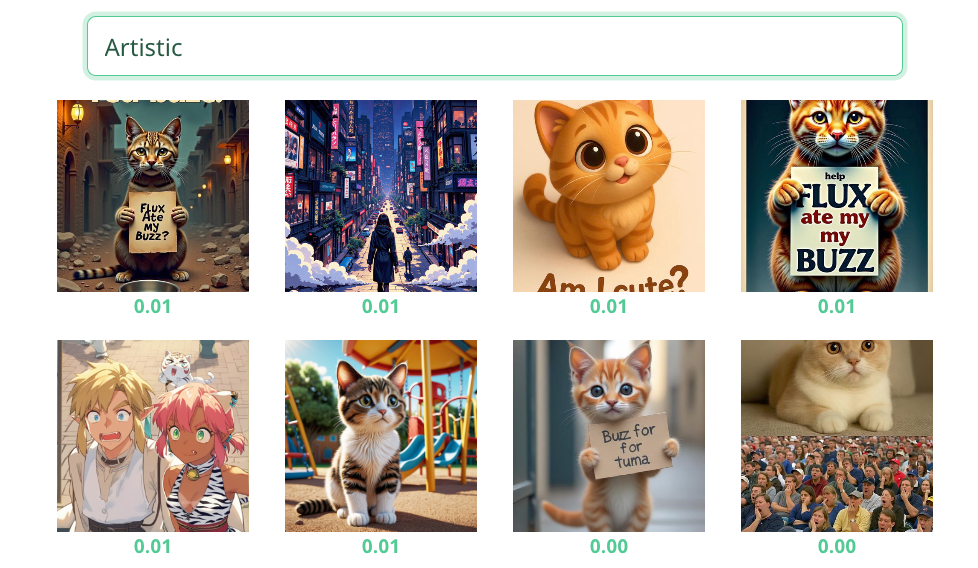 |
Terrible Performance |
 |
3 out of 13 Ok Performance |
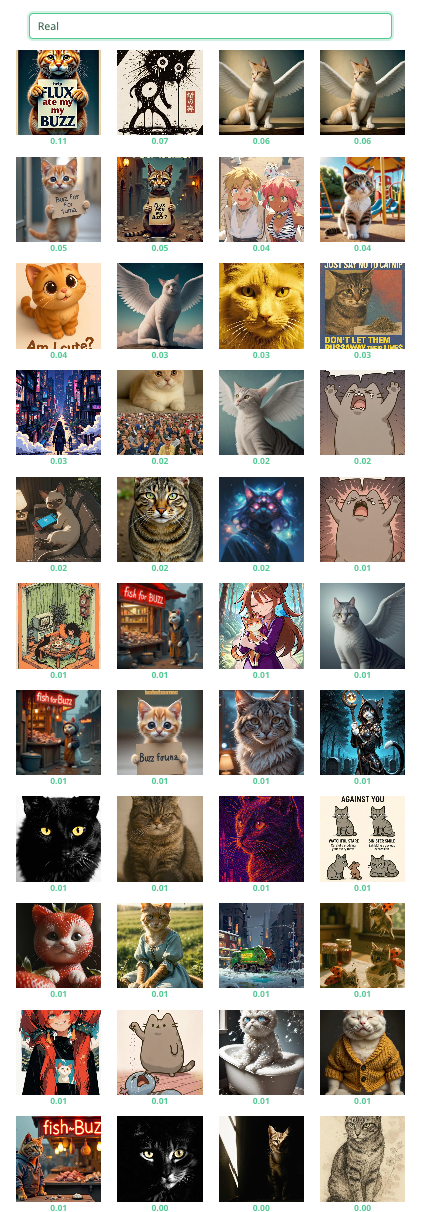 |
8 out of 15 Good Performance |
 |
11 out of 13 Strong Performance |
This demonstrates that the model excels at detecting overt visual markers of realism or fantasy but struggles profoundly with culturally nuanced or conceptually abstract categories. The results align with Distant Viewing’s observation that AI systems often recognize ‘what’ is depicted more readily than ‘how’ or ‘why’—prioritizing literal features over stylistic intent or emotional resonance. Particularly telling is the humor detection failure, suggesting the model lacks training in internet meme semiotics where absurdity and irony dominate. These limitations expose how even multimodal models remain constrained by their training data’s cultural priorities and object-centric biases.
4.3 Generate 2D Clip
I uploaded all images with prompts into 2D clip. the follwoing is an analysis of the images how real it is and artisitc.
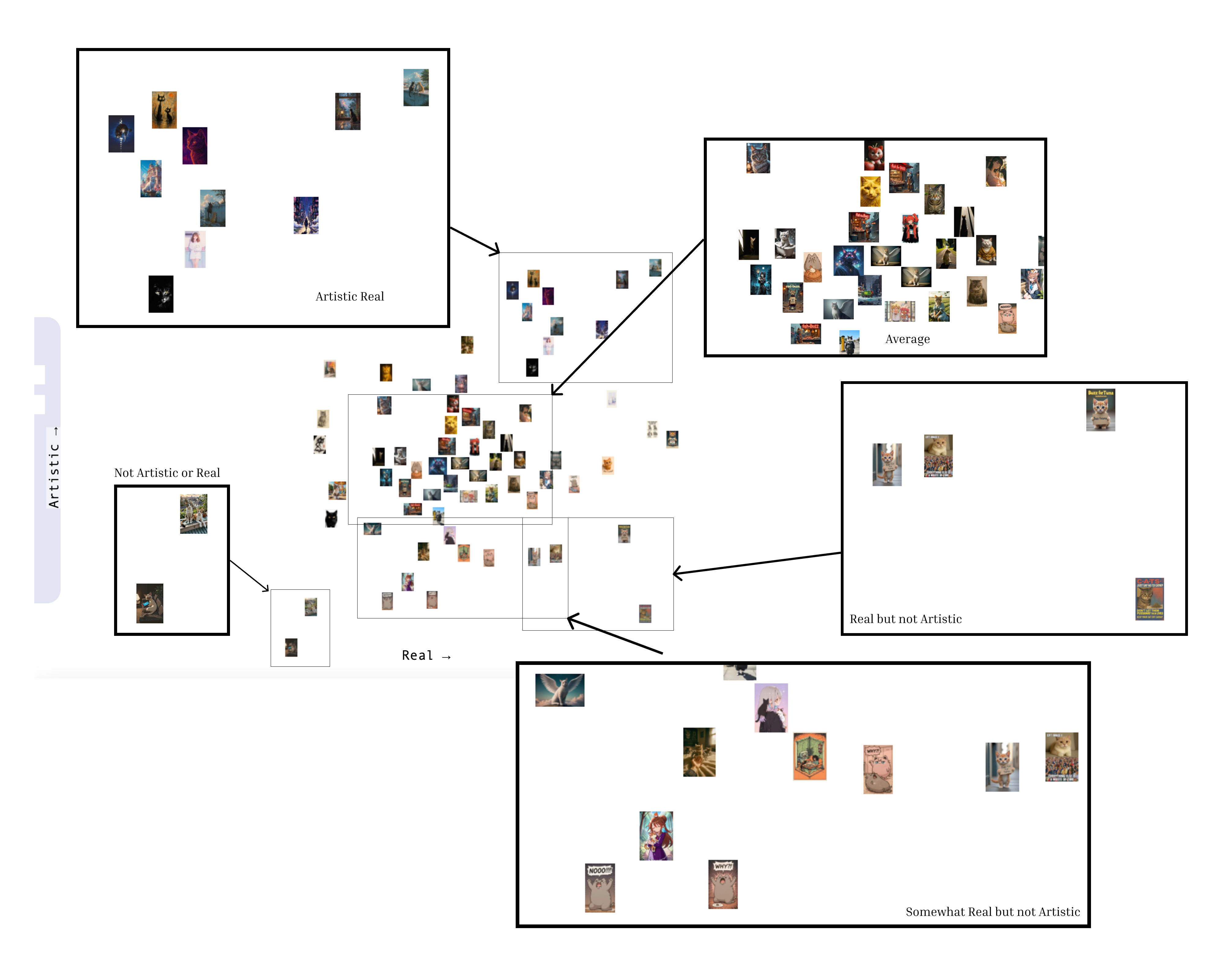 Interestingly, most of the cartoon-style images are positioned in the “real” category rather than being labeled as “artistic,” which challenges the common assumption that drawings are inherently artistic. Image 6 and Image 19 stand out as neither realistic nor artistic—Image 19 appears artificial and puppet-like, which may contribute to its lack of realism or artistic value, while Image 6, although clearly a cartoon, lacks the expressive or stylized qualities typically associated with artistic depictions. Notably, all the cat images are consistently rated as realistic, perhaps due to the model’s training data containing many cat photos or because cats are relatively easy to render believably. In contrast, images categorized as artistic tend to exhibit dramatic shifts in style, vibrant color contrasts, or unique visual palettes that set them apart from both realistic and cartoon imagery.
Interestingly, most of the cartoon-style images are positioned in the “real” category rather than being labeled as “artistic,” which challenges the common assumption that drawings are inherently artistic. Image 6 and Image 19 stand out as neither realistic nor artistic—Image 19 appears artificial and puppet-like, which may contribute to its lack of realism or artistic value, while Image 6, although clearly a cartoon, lacks the expressive or stylized qualities typically associated with artistic depictions. Notably, all the cat images are consistently rated as realistic, perhaps due to the model’s training data containing many cat photos or because cats are relatively easy to render believably. In contrast, images categorized as artistic tend to exhibit dramatic shifts in style, vibrant color contrasts, or unique visual palettes that set them apart from both realistic and cartoon imagery.
5 Overall
5.1 Summary
This assignment has provided a comprehensive examination of AI’s ability to recognize and classify attributes of AI-generated cat images sourced from CIVITAI. By analyzing how well AI models can identify predefined attributes such as Realistic, Artistic, Surreal, Humorous, and Abstract, we aimed to assess the accuracy and reliability of these models in interpreting visual data. This study not only evaluates the technical performance of AI but also explores the broader implications of AI-driven image classification in the context of digital content creation.
5.2 Key Insights
The analysis has revealed several key insights into the capabilities and limitations of AI in image classification and caption generation:
- Algorithm Performance: Different algorithms showed varied levels of performance in classifying images based on their attributes. Some algorithms were more effective at identifying thematic elements and common traits, while others struggled with accurate categorization based on predefined attributes.
- Misclassification Accuracy: The AI’s ability to accurately classify images into the established categories was inconsistent. Some images could be considered for multiple categories but were placed in one due to the AI’s interpretation.
- Understanding of Stylized Content: The AI’s failure was most evident in anime or fantasy-style images, where specific details—like character design, pose, environment, or emotional tone—were critical to the meaning. Models prioritized generic or misclassified elements, overlooking key narrative signals.
- Semantic Blindness: The AI’s failure to accurately reflect the complex and nuanced content described in the prompts indicates a semantic blindness in stylized content. The models often struggled with context recognition, especially in stylized or surreal images.
- Bias in Dataset: Some classifications revealed latent biases in the dataset used to train the model, highlighting how irrelevant features can dominate AI perception.
5.3 Takeaway
The findings from this assignment suggest that while AI has made significant strides in image recognition and classification, there is still considerable room for improvement, particularly in how AI interprets and categorizes visual data based on textual descriptions and cultural contexts.
This analysis, combined with insights from Distant Viewing (Arnold & Tilton), suggests that while AI has made significant progress in image classification, the journey towards AI that can truly understand and interpret visual culture is ongoing and requires further refinement and understanding of the nuances in visual data.
✅ Ready for Grading
Due: May 11, 2025 23:59 PM